



 BIG DATA
BIG DATA
BIG DATA
BIG DATA
BIG DATA
Our research and analysis point to a new modern data stack that is emerging where apps will be built from a coherent set of data elements that can be composed at scale.
Demand for these apps will come from organizations that wish to create a digital twin of their business to represent people, places, things and the activities that connect them, to drive new levels of productivity and monetization. Further, we expect Snowflake Inc., at its upcoming conference, will expose its vision to be the best platform on which to develop this new breed of data apps. In our view, Snowflake is significantly ahead of the pack but faces key decision points along the way to its future to protect this lead.
In this Breaking Analysis and ahead of Snowflake Summit later this month, we lay out a likely path for Snowflake to execute on this vision, and we address the milestones and challenges of getting there. As always, we’ll look at what the Enterprise Technology Research data tells us about the current state of the market. To do all this we welcome back George Gilbert, a contributor the theCUBE, SiliconANGLE Media’s video studio.
The graphic below describes how we see this new data stack evolving. We see the world of apps moving from one that is process-centric to one that is data-centric, where business logic is embedded into data versus today’s stovepiped model where data is locked inside application silos.
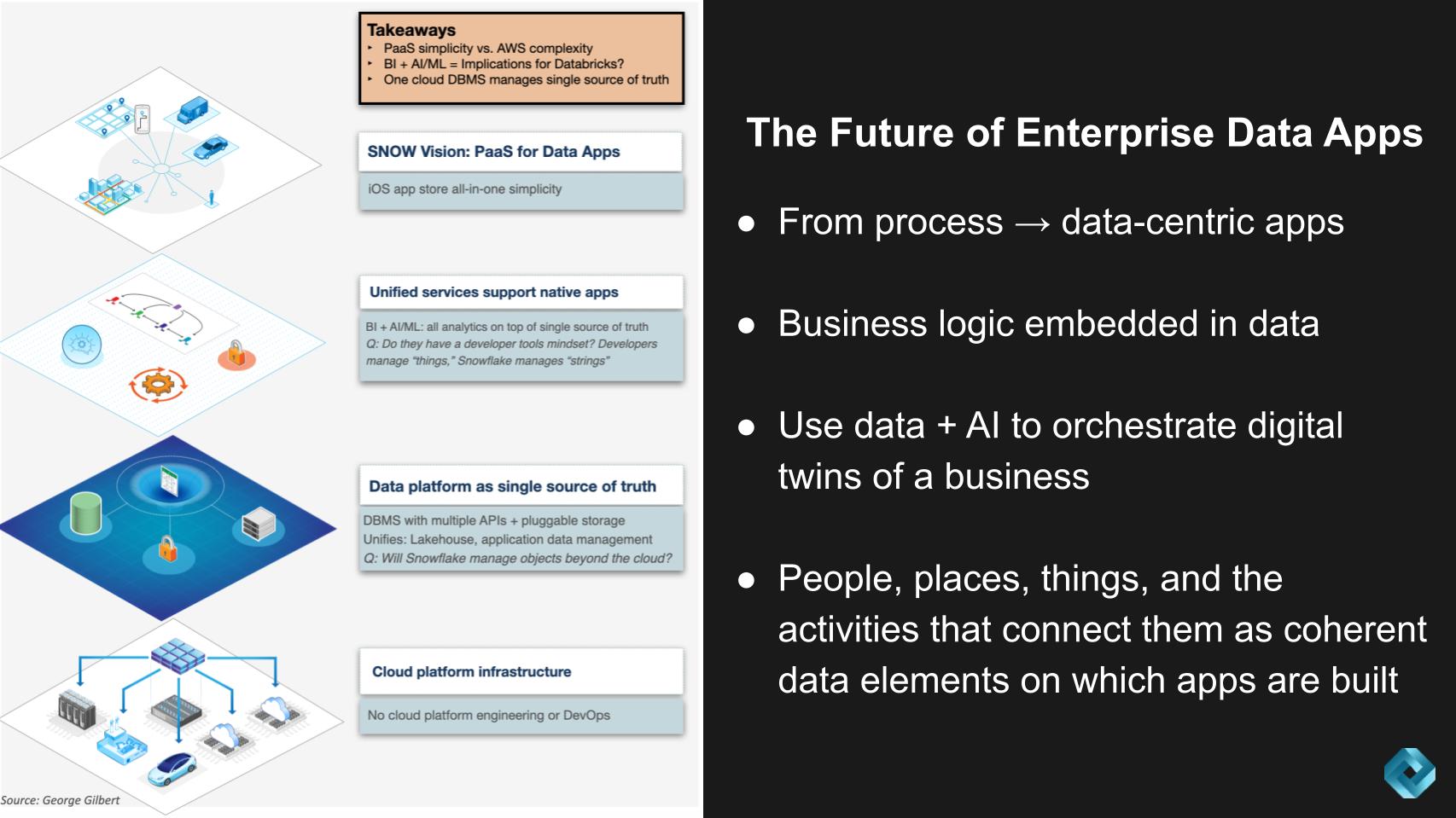
There are four layers to the emerging data stack supporting this premise.
Starting at the bottom is the infrastructure layer, which we believe increasingly is being abstracted to hide underlying cloud and cross-cloud complexity — what we call supercloud.
Moving up the stack is the data layer that comprises multilingual databases, multiple application programming interfaces and pluggable storage.
Continuing up the stack is a unified services layer that brings together business intelligence and artificial intelligence/machine learning into a single platform.
Finally there’s the platform-as-a-service for data apps at the top of the picture, which defines the overall user experience as one that is consistent and intuitive.
Here’s a summary of Gilbert’s key points regarding this emerging stack:
The picture above underscores a significant shift in application development paradigms. Specifically, we’re transitioning away from an era dominated by standalone Web 2.0 apps, featuring microservices and isolated databases, toward a more integrated and unified development environment. This new approach focuses on managing “people, places and things” – and describes a movement from data strings to tangible things.
Key takeaways include:
This suggests a compelling trend for stakeholders to watch. The advent of a more unified and integrated development environment is a game-changing evolution. It encourages stakeholders to consider solutions like Snowflake, which simplifies and enhances the development process, thereby promoting efficiency, reducing complexity and driving new levels of monetization.
The key question is: Can Snowflake execute on this vision and can they move faster than competitors including the hyperscalers and Databricks Inc., which we’ll discuss later in this research.
Listen to George Gilbert describe the new modern data stack.
Let’s revisit the Uber analogy that we’ve shared before.
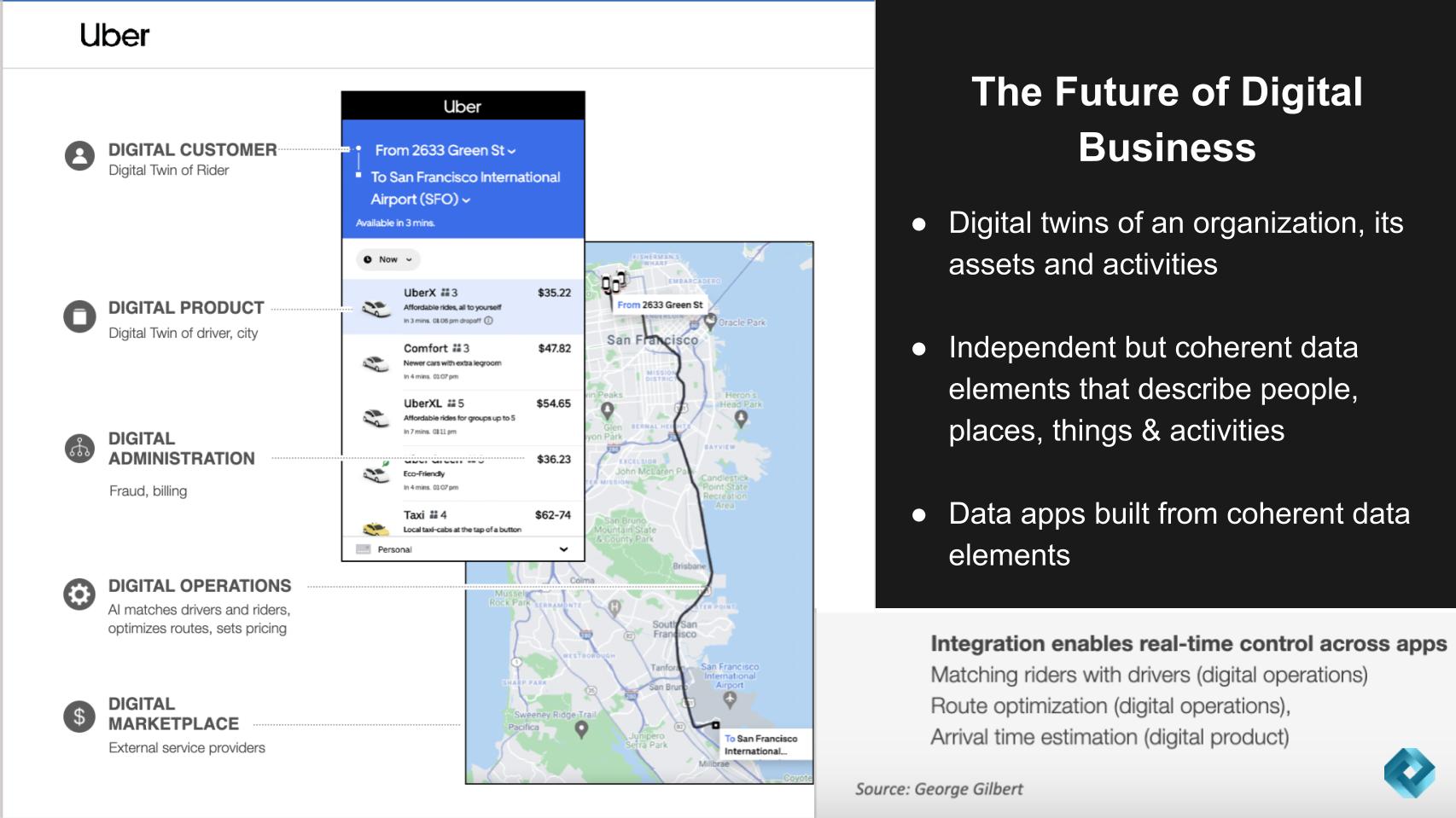
The idea described above is that the future of a digital business will manifest to a digital twin of an organization. The example we use frequently is Uber for business where, in the case of Uber Technologies Inc., drivers, riders, destinations, estimated times of arrival, and the transactions that result from real-time activities have been built by Uber into a set of applications where all these data elements are coherent and can be joined together to create value, in real time.
Here’s a summary of Gilbert’s take on why this is such a powerful metaphor:
We believe the paradigm shift in application development will increasingly focus on applications being organized around real-world entities such as people, places, things and activities. This evolution reduces the gap between a developer’s conceptual thinking and the real-world business entities that need management.
Key points include:
We believe the vision presented by Gilbert has profound implications for those involved in application development. It’s important for stakeholders to realize that the new era of applications calls for a different kind of thinking – one that aligns with orchestrating real-world activities through a unified, coherent development environment. This has the potential to increase efficiency dramatically and enable more complex, autonomous operations.
A major barrier today is that only companies such as Uber, Google LLC, Amazon.com Inc. and Meta Platforms Inc. can build these powerful data apps. Starting 10-plys years ago, the technical teams at these companies have had to wrestle with MapReduce code and dig into TensorFlow libraries in order to build sophisticated models. Mainstream companies without thousands of world class developers haven’t just been locked out of the data apps game, they’ve been unable to remake their businesses as platforms.
To emphasize our premise, we believe the industry generally and Snowflake specifically are moving to a world beyond today’s Web 2.0 programming paradigm where analytics and operational platforms are separate and the application logic is organized through microservices. We see a world where these types of systems are integrated and BI is unified with AI/ML. And a semantic layer organizes application logic to enable all the data elements to be coherent.
In our view, a main thrust of Snowflake’s application platform strategy will be to simplify the experience dramatically for developers while maintaining the promise of Snowflake’s data sharing and governance model.

Here are the critical points from the discussion with Gilbert on this topic:
Our research points to a vital trend for observers to monitor. The democratization of app development capabilities through platforms such as Snowflake and Databricks. This is fundamental in our view and the shift has the potential to level the playing field, allowing a wider range of organizations to harness the power of sophisticated data applications.
Snowflake bristles at the idea that it is a data warehouse vendor. Although the firm got its foothold by disrupting traditional enterprise data warehouse markets, it has evolved into a true platform. We think a main thrust of that platform is an experience that promises consistency and governed data sharing on and across clouds. The company’s offering continues to evolve to support any data type through pluggable storage and the ability to extend this promise to materialized views, which implies a wider scope.
We believe the next wave of opportunity for Snowflake (and its competitors) is building modern data apps. It’s clear to us that Snowflake wants to be the No. 1 place in the world to build these apps – the iPhone of data apps, if you will. But more specifically, Snowflake in our view wants to be the preferred platform, meaning the fastest time to develop, the most cost-effective, the most secure and most performant place to build and monetize data apps.
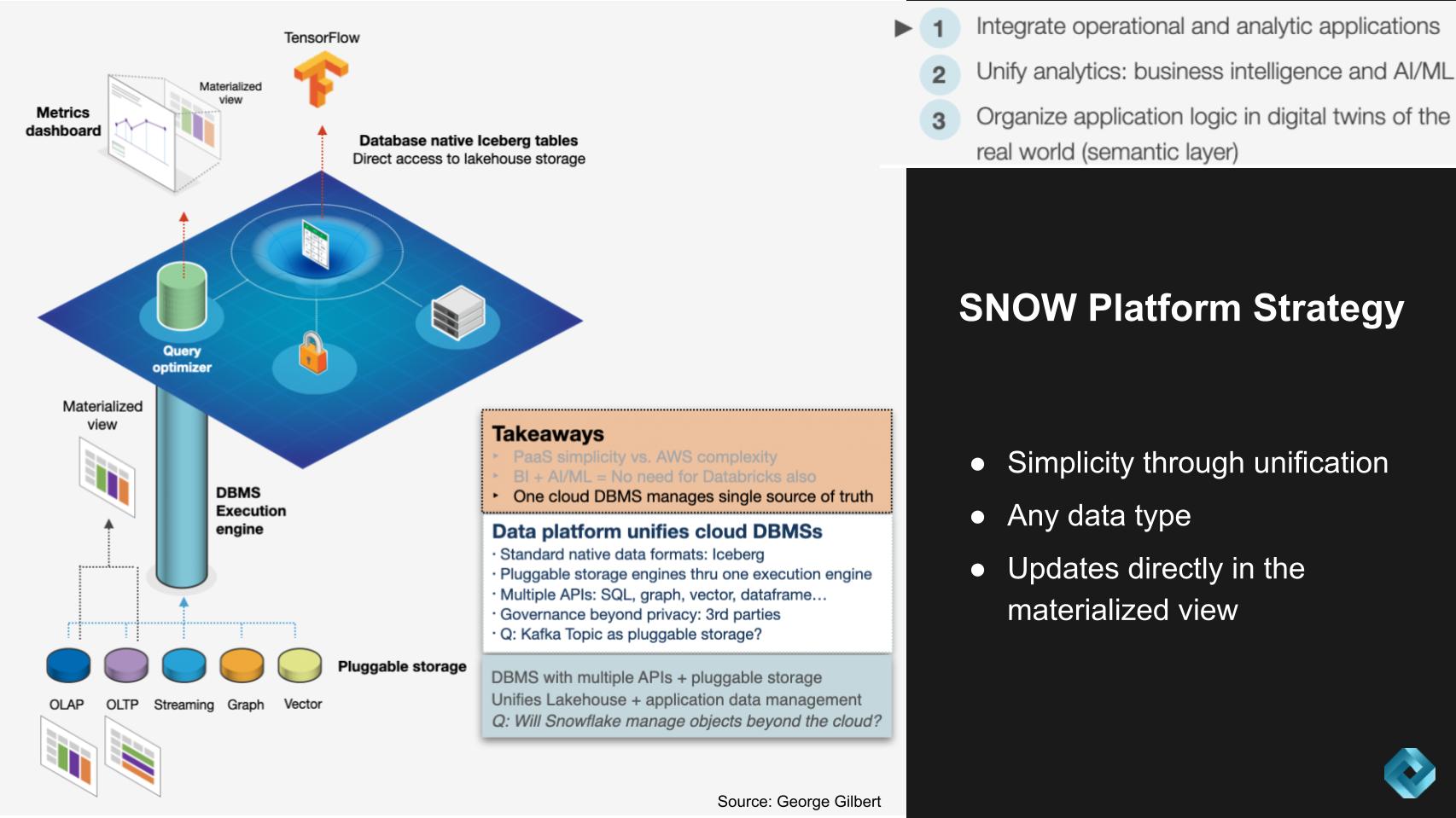
The following summarizes our view and the conversation with Gilbert on this topic:
One of the core principles of this new modern data stack is supporting all data types and workloads, with Snowflake being a key player in this regard. We believe Snowflake is essentially revolutionizing the data platform, providing a more simplified, yet potent tool for developers to work with.
Crucial points from our analysis include:
Bottom Line: Our research points to a transformative shift in data management. In the legacy era when everything was on-premises, Oracle managed the operational data while Teradata and others, including Oracle, managed separate analytic data. Snowflake aspires to manage everything from that era and more. Snowflake’s pursuit of unification and simplification offers a considerable boon for developers and organizations alike, paving the way for a future where handling diverse data types and workloads becomes commonplace. This trend is one to watch closely, as it could profoundly shape the data management landscape.
Watch this five-minute deep dive into where we see the Snowflake platform architecture heading.
Unifying BI and AI/ML is a critical theme of the new modern data stack. The slide below shows Snowflake on the left hand side, Databricks on the right, and we see these worlds coming together.
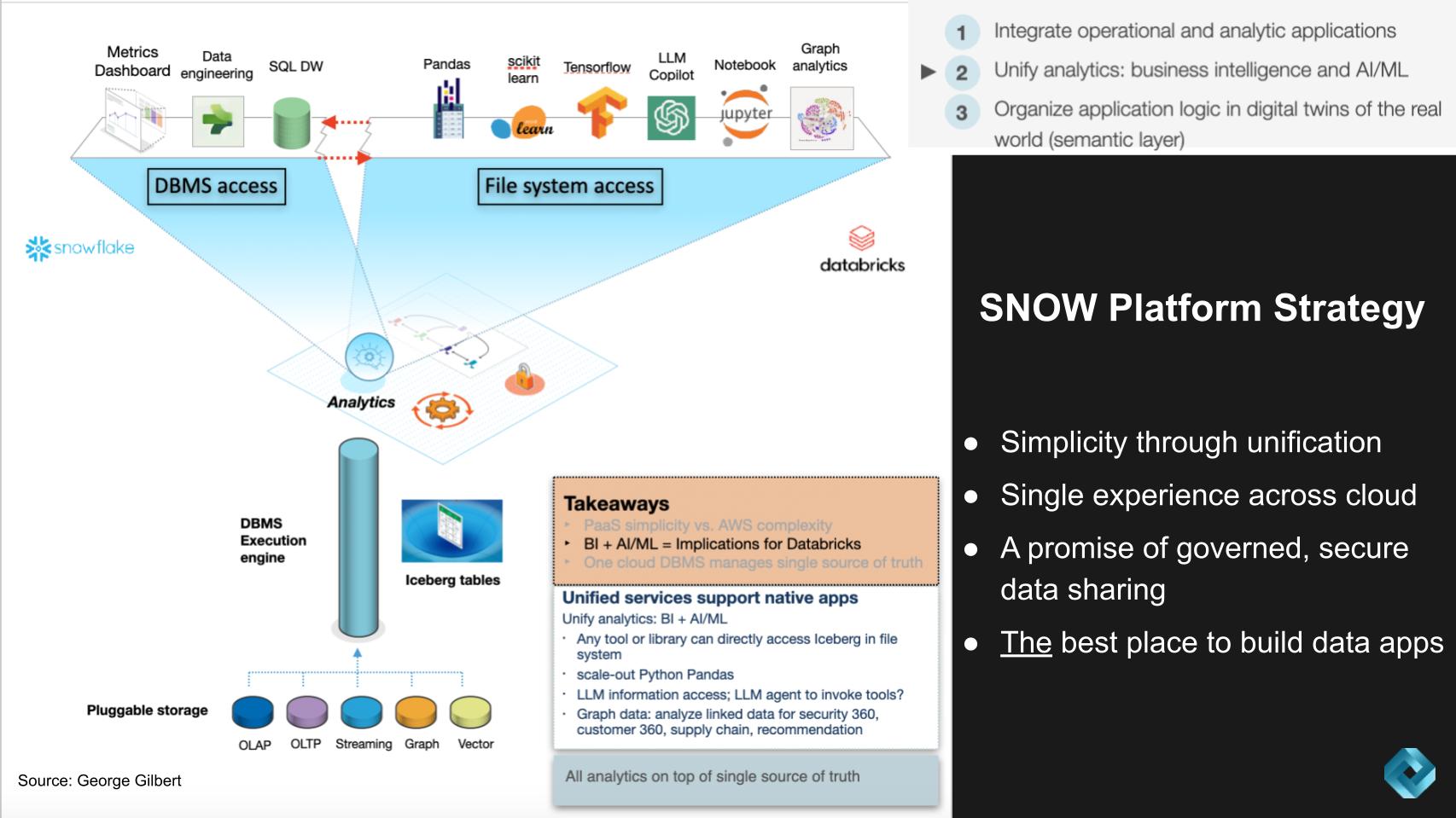
The important points of this graphic and the implications for Databricks, Snowflake and the industry in general can be summarized as follows:
The dynamics between Snowflake and Databricks, two key players in the field of business intelligence and AI/ML, are evolving rapidly. Snowflake has made strides in order to try and eliminate the need for Databricks in some contexts, while Databricks is attacking Snowflake’s stronghold in analytics.
To date, if a customer wanted the best BI and AI/ML support, they needed both Databricks and Snowflake. Each is trying to be a one-stop-shop. Customers should not have to move data between platforms to perform alternately BI and AI/ML.
There has been talk that it would be harder for Snowflake to build Databricks’ technology than vice-versa. The assumption behind that thinking seems to be that BI is old, well-understood technology and AI/ML is newer and less well-understood. But that glosses over the immense difficulty of building a multiworkload, multimodel cloud-scale DBMS. It’s still one of the most challenging products in enterprise software. As Andy Jassy used to say, there’s no compression algorithm for experience. While others are catching up with BI workload support, Snowflake has moved on to transactional workloads and now pluggable data models.
On the tools and API side, Snowflake is adding new APIs to support personas that weren’t as well-supported, such as data science and engineering.
The dynamics between Snowflake and Databricks, two key players in the field of business intelligence and AI/ML, are evolving rapidly. Snowflake has made strides in order to try and eliminate the need for Databricks in some contexts, while Databricks is attacking Snowflake’s stronghold in analytics.
Key points include:
Our research indicates that Snowflake is making significant strides towards becoming a one-stop solution that can cater to all data types and workloads. This paradigm shift has the potential to substantially alter the dynamics of the industry, making it a top level trend to follow for analysts and businesses technologists.
Basically you’ll be able to take your laptop-based, Python and Pandas data science and data engineering code, and scale it out directly to run on the Snowflake cluster with extremely high compatibility. The numbers we’ve seen are 90% to 95% compatibility. So you might have this situation where it’s more compatible to go from Python on your laptop to Python on Snowflake than Python on Spark. So that’s an example of one case where Snowflake is taking the data science tools that you used to have to go to Databricks for and supporting them natively on Snowflake.
Watch this four-minute deep dive into how Snowflake is unifying BI and AI/ML workloads.
We’re going to take a break from George’s excellent graphics and come back to the survey data. Let’s answer the following question: To what degree do Snowflake and Databricks customers overlap in the same accounts?
This is the power of the ETR platform where we can answer these questions over a time series.

This chart above shows what the presence of Databricks is inside of 302 Snowflake accounts within the ETR survey base. The vertical axis is Net Score or spending momentum and the horizontal axis shows the overlap. We’re plotting Databricks and we added in Oracle for context.
Thirty-six percent of those Snowflake accounts are also running Databricks. That jumps to 39% if you take Streamlit out of the numbers. And notably this figure is up from 17% two years ago and 14% two years ago without Streamlit.
The point is Databricks’ presence inside of Snowflake accounts has risen dramatically in the past 24 months. And that’s a warning shot to Snowflake.
As an aside, Oracle is present in 69% of Snowflake accounts.
Now let’s flip the picture — in other words, how penetrated is Snowflake inside Databricks accounts, which is what we show below. As you can see, that number is 48%, but that’s only up slightly from 44% two years ago. So Databricks, despite the growth of Snowflake over the past two years, is more prominent in terms of penetrating Snowflake accounts.
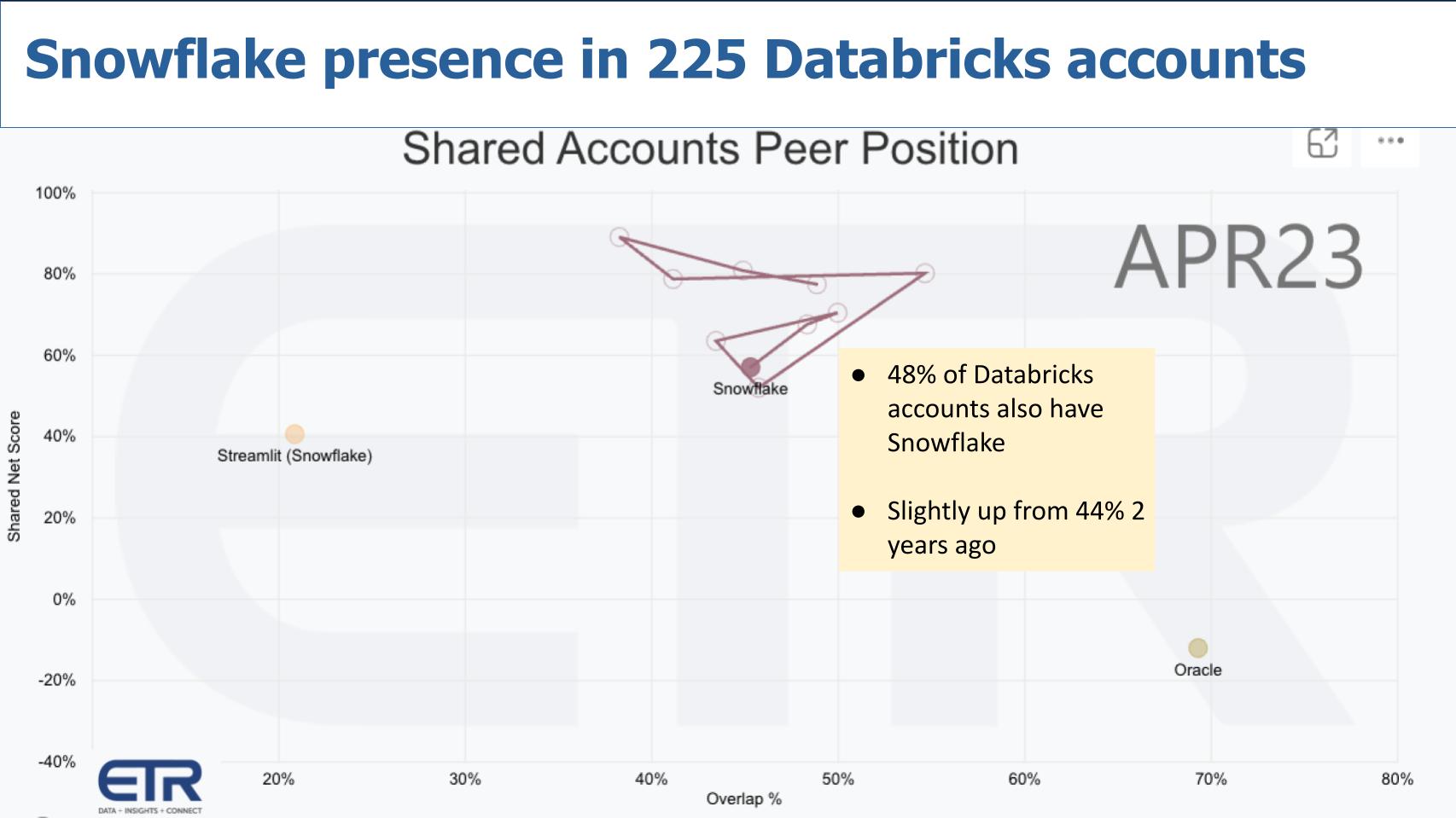
Here’s our summary of the overlap between these two platforms:
We believe the maturity of organizations in terms of their data platform utilization is evolving rapidly. The increasing overlap between Snowflake and Databricks can be seen as a response to these companies’ realization that to extract maximum value from their data, they need to address both business intelligence and AI/ML workloads.
Key takeaways from this analysis include:
Our research indicates a dynamic environment where data platforms are progressively diversifying their capabilities. With Snowflake making notable progress in addressing data science and engineering workloads, organizations may need to reassess their data strategy to maximize value from these evolving platforms. Databricks is not standing still and its growth rates, based on our information, continue to exceed those of Snowflake, albeit from a smaller revenue base.
Let’s now jump to the third key pillar, which brings us deeper into the semantic layer.
The graphic below emphasizes the notion of organizing application logic into digital twins of a business. Our assertion is this fundamentally requires a semantic layer. This is one area where are research is inconclusive with regard to Snowflake’s plans. Initially we felt that Snowflake could take an ecosystem approach and allow third parties to manage the semantic layer. However, we see this as a potential blind spot to Snowflake and could pose the risk of losing control of the full data stack.
A summary of our analysis follows:

The semantic layer is starting to emerge as BI metrics. These metrics, like bookings, billings and revenue, or more specific examples like Uber’s rides per hour, were traditionally managed by BI tools. These tools had to extract data from the database to define and update these metrics, which was a challenging and resource-intensive process.
Semantic layer implementation: Snowflake in our view intends to take on the critically demanding task of supporting these metrics. It will cache the live, aggregated data that will allow BI tool users to slice and dice by dimension. We believe it plans to support third parties, such as AtScale Inc., dbt Labs Inc. and Google-owned Looker, to define the metrics and dimensions. Previously, such tools typically had to cache data extracts outside the DBMSs themselves. This approach fits with Snowflake’s business model of supporting an ecosystem of tools.
In essence, we believe that that if Snowflake’s approach to handling the semantic layer within its platform is to leave that to third parties, it might be too narrow and potentially misses the broader implications and challenges of application semantics.
Let’s double-click on this notion of the semantic layer and its importance. Further, we want to explore what it means for Snowflake in terms of who owns the semantic layer and how to translate the language of people, places and things into the language of databases.
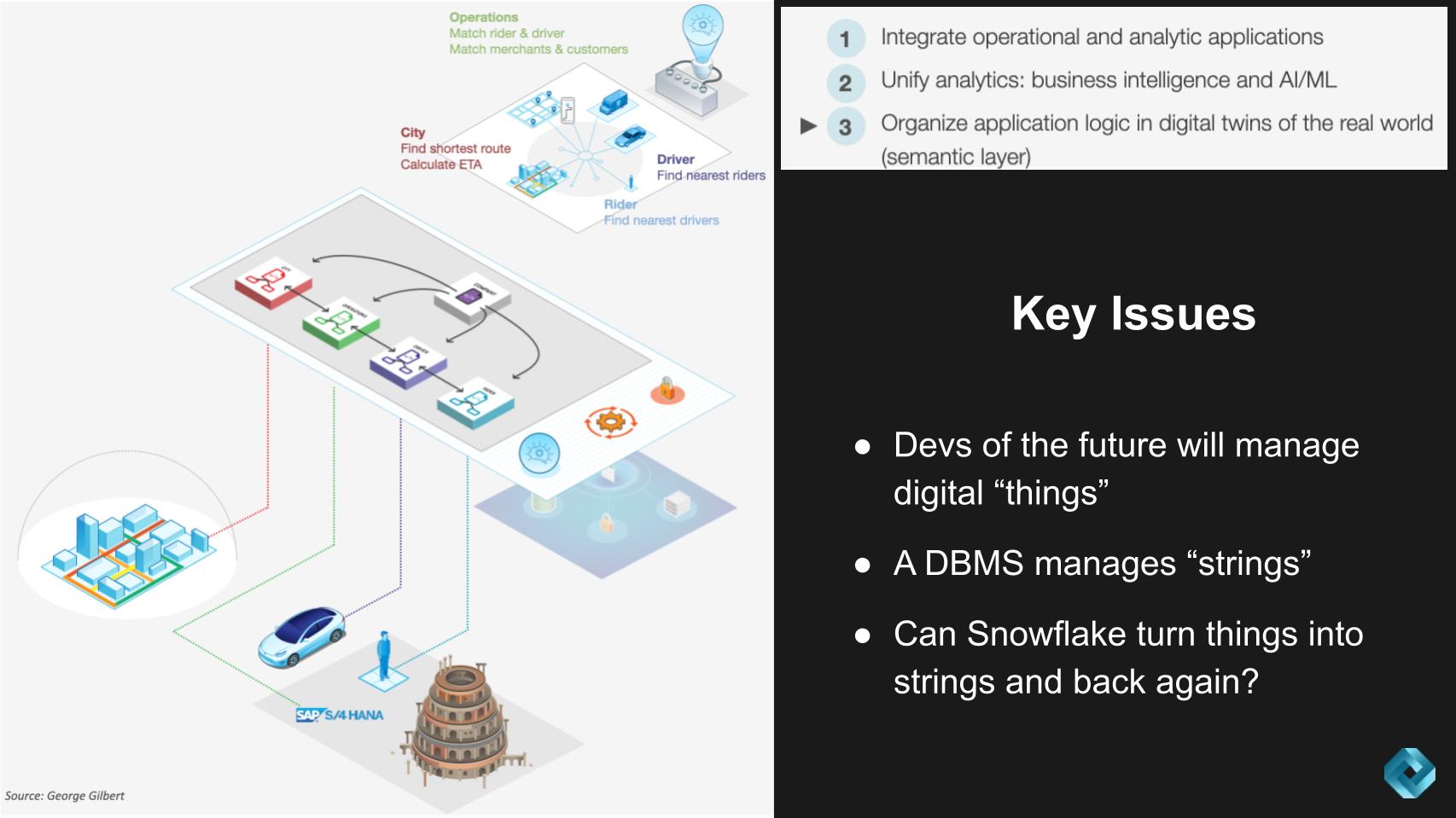
In essence, we believe that if Snowflake’s approach to handling the semantic layer within its platform is to leave it to third parties, they may lose control of the application platform and their destiny.
Snowflake aspires to build a platform for applications that handles all data and workloads. In the 1990s, Oracle wanted developers to code application logic in their tools and in the DBMS stored procedures. But Oracle lost control of the application stack as SAP, PeopleSoft and then the Java community around BEA all built a new layer for application logic. That’s the risk if Snowflake doesn’t get this layer right.
Watch this two-minute riff on why Snowflake may want to vertically integrate the semantic layer.
Let’s examine the horses on the track in this race. The Belmont stakes is this weekend. It’s a grueling, mile-and-a-half race… it’s not a sprint. Below we take a look at the marathon runners in the world of cloud data platforms.
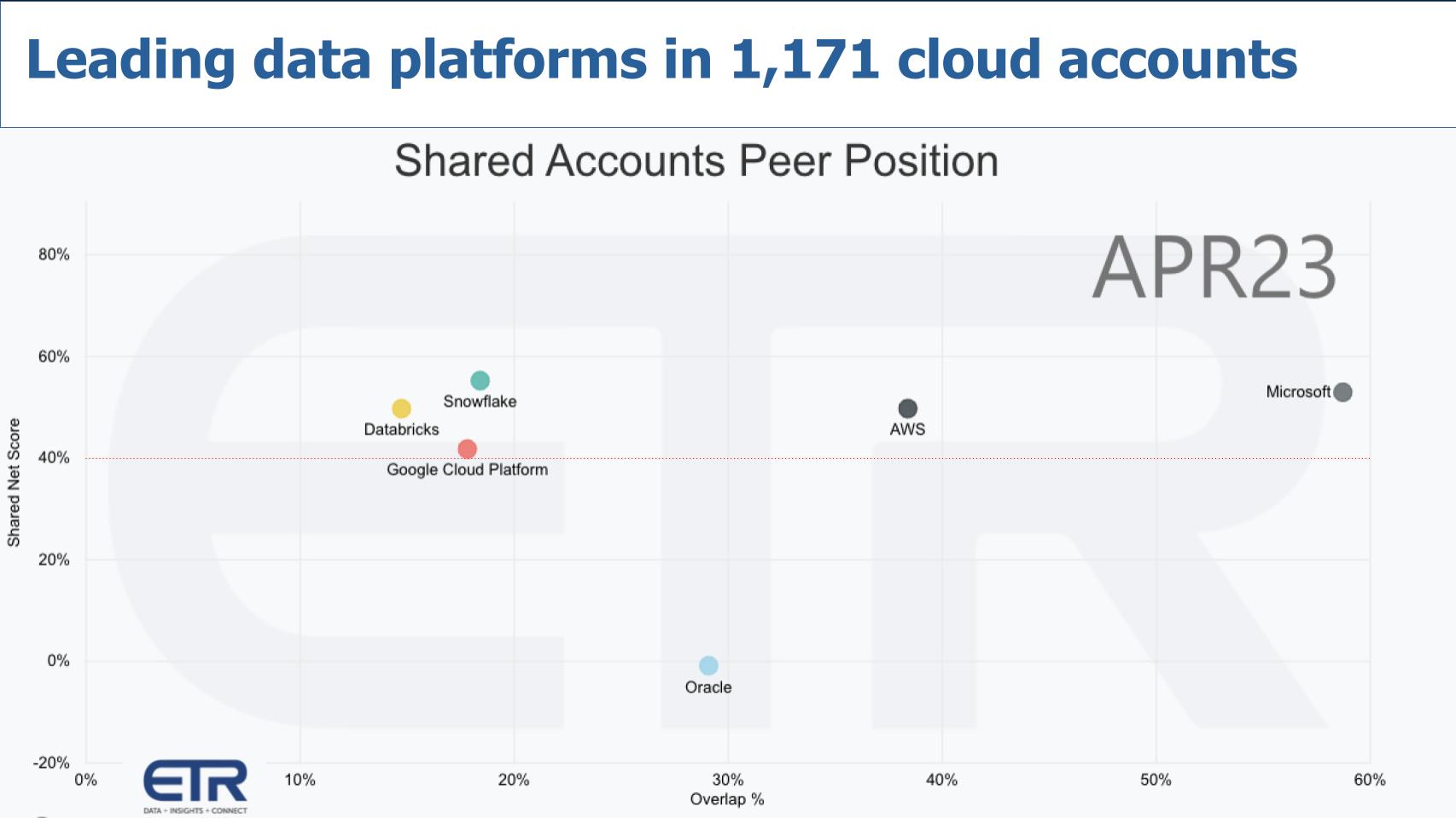
The graphic above uses the same dimensions as earlier, Net Score or spending momentum on the Y axis and the N overlap within a filter of 1,171 cloud accounts in the ETR data set. That red line at 40% indicates a highly elevated Net Score.
Microsoft just announced Fabric. By virtue of its size and simple business model (for customers), it is furthest up to the right in spending metrics and market presence. Not necessarily function but the model works. AWS is “gluing” together its various data platforms that are successful. Google has a killer product in Big Query, with perhaps the best AI chops in the business, but is behind in both momentum and market presence. Databricks and Snowflake both have strong spending momentum notwithstanding that Snowflake’s Net Score has been in decline since the January 2022 survey peak. Howeve, both Snowflake’s and Databricks’ Net Scores are highly elevated.
Here’s our overall analysis of the industry direction:
The big change is we believe the market will increasingly demand unification and simplification. It starts with unifying the data, so that your analytic data is in one place. So first, there’s one source of truth for analytic data. Then we’ll add to that one source of truth all your operational data. Then build one uniform engine for accessing all that data and then that unified application stack that maps people, places, things and activities to that one source of truth.
Here’s our assessment of the leading players:
The overall theme of our analysis suggests that these major providers are working towards consolidating and streamlining their data architectures to facilitate a single source of truth, including both analytic and operational data, making it easier to build and manage data apps. However, each of these platforms has its unique set of challenges in achieving this goal.
Let’s close with the key issues we’ll be exploring at Snowflake Summit and Databricks events, which take place the same week in late June. We’re going to start at the bottom layer of the stack in the chart below and work our way up the stack down on this slide.

Before we get into the stack, one related area we’re exploring is Snowflake’s strategy of managing data outside the cloud. It’s unclear how Snowflake plans to accommodate this data. We’ve seen some examples of partnerships with Dell Technologies Inc., but at physical distances there are questions about its capacity to handle tasks like distributed joins. We wonder how it would respond if data egress fees were not a factor.
Moving to the stack:
We expect to get more clues and possibly direct data from Snowflake (and Databricks) later this month.
As well, we continue to research the evolution of cloud computing. We’re reminded of the Unix days, where the burden of assembling services fell on the developer. We see Snowflake’s approach as an effort to simplify this approach by offering a more integrated and coherent development stack.
Lastly, Snowflake plays in a highly competitive landscape where companies such as Amazon, Databricks, Google and Microsoft constantly add new features to their platforms. Nonetheless, we believe Snowflake continues be ahead and has positioned itself as a company that can utilize the robust infrastructure of the cloud (primarily AWS) but simultaneously simplify the development of data apps.
On balance, this will require a developer tools mindset and force Snowflake to move beyond its database comfort zone — a nontrivial agenda that could reap massive rewards for the company and its customers.
Many thanks to George Gilbert for his collaboration on this research. Thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight, who help us keep our community informed and get the word out, and to Rob Hof, our editor in chief at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com, DM @dvellante on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
Here’s the full video analysis:
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
THANK YOU





